Кластерный анализ
Большинство исследователей склоняются к тому, что впервые термин «кластерный анализ» (англ. cluster - гроздь, сгусток, пучок) был предложен математиком Р.Трионом . Впоследствии возник ряд терминов, которые в настоящее время принято считать синонимами термина «кластерный анализ»: автоматическая классификация; ботриология.
Кластерный анализ - это многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы (кластеры)(Q-кластеризация, или Q-техника, собственно кластерный анализ). Кластер - группа элементов, характеризуемых общим свойством, главная цель кластерного анализа - нахождение групп схожих объектов в выборке. Спектр применений кластерного анализа очень широк: его используют в археологии, медицине, психологии, химии, биологии, государственном управлении, филологии, антропологии, маркетинге, социологии и других дисциплинах. Однако универсальность применения привела к появлению большого количества несовместимых терминов, методов и подходов, затрудняющих однозначное использование и непротиворечивую интерпретацию кластерного анализа. Орлов А. И. предлагает различать следующим образом:
Задачи и условия
Кластерный анализ выполняет следующие основные задачи :
- Разработка типологии или классификации.
- Исследование полезных концептуальных схем группирования объектов.
- Порождение гипотез на основе исследования данных.
- Проверка гипотез или исследования для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Независимо от предмета изучения применение кластерного анализа предполагает следующие этапы :
- Отбор выборки для кластеризации. Подразумевается, что имеет смысл кластеризовать только количественные данные.
- Определение множества переменных, по которым будут оцениваться объекты в выборке, то есть признакового пространства.
- Вычисление значений той или иной меры сходства (или различия) между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов.
- Проверка достоверности результатов кластерного решения.
Кластерный анализ предъявляет следующие требования к данным :
- показатели не должны коррелировать между собой;
- показатели не должны противоречить теории измерений;
- распределение показателей должно быть близко к нормальному;
- показатели должны отвечать требованию «устойчивости», под которой понимается отсутствие влияния на их значения случайных факторов;
- выборка должна быть однородна, не содержать «выбросов».
Можно встретить описание двух фундаментальных требований предъявляемых к данным - однородность и полнота:
Однородность требует, чтобы все сущности, представленные в таблице, были одной природы. Требование полноты состоит в том, чтобы множества I и J представляли полную опись проявлений рассматриваемого явления. Если рассматривается таблица в которой I - совокупность, а J - множество переменных, описывающих эту совокупность, то должно должно быть представительной выборкой из изучаемой совокупности, а система характеристик J должна давать удовлетворительное векторное представление индивидов i с точки зрения исследователя .
Если кластерному анализу предшествует факторный анализ , то выборка не нуждается в «ремонте» - изложенные требования выполняются автоматически самой процедурой факторного моделирования (есть ещё одно достоинство - z-стандартизация без негативных последствий для выборки; если её проводить непосредственно для кластерного анализа, она может повлечь за собой уменьшение чёткости разделения групп). В противном случае выборку нужно корректировать.
Типология задач кластеризации
Типы входных данных
В современной науке применяется несколько алгоритмов обработки входных данных. Анализ путём сравнения объектов, исходя из признаков, (наиболее распространённый в биологических науках) называется Q -типом анализа, а в случае сравнения признаков, на основе объектов - R -типом анализа. Существуют попытки использования гибридных типов анализа (например, RQ -анализ), но данная методология ещё должным образом не разработана.
Цели кластеризации
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй »).
- Сжатие данных . Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны (англ. novelty detection ). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Во всех этих случаях может применяться иерархическая кластеризация , когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии . Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому.
Методы кластеризации
Общепринятой классификации методов кластеризации не существует, но можно отметить солидную попытку В. С. Берикова и Г. С. Лбова . Если обобщить различные классификации методов кластеризации, то можно выделить ряд групп (некоторые методы можно отнести сразу к нескольким группам и потому предлагается рассматривать данную типизацию как некоторое приближение к реальной классификации методов кластеризации):
- Вероятностный подход . Предполагается, что каждый рассматриваемый объект относится к одному из k классов. Некоторые авторы (например, А. И. Орлов) считают, что данная группа вовсе не относится к кластеризации и противопоставляют её под названием «дискриминация», то есть выбор отнесения объектов к одной из известных групп (обучающих выборок).
- Подходы на основе систем искусственного интеллекта . Весьма условная группа, так как методов AI очень много и методически они весьма различны.
- Логический подход . Построение дендрограммы осуществляется с помощью дерева решений.
- Теоретико-графовый подход
.
- Графовые алгоритмы кластеризации
- Иерархический подход
. Предполагается наличие вложенных групп (кластеров различного порядка). Алгоритмы в свою очередь подразделяются на агломеративные (объединительные) и дивизивные (разделяющие). По количеству признаков иногда выделяют монотетические и политетические методы классификации.
- Иерархическая дивизивная кластеризация или таксономия. Задачи кластеризации рассматриваются в количественной таксономии.
- Другие методы
. Не вошедшие в предыдущие группы.
- Статистические алгоритмы кластеризации
- Ансамбль кластеризаторов
- Алгоритмы семейства KRAB
- Алгоритм, основанный на методе просеивания
- DBSCAN и др.
Подходы 4 и 5 иногда объединяют под названием структурного или геометрического подхода, обладающего большей формализованностью понятия близости . Несмотря на значительные различия между перечисленными методами все они опираются на исходную «гипотезу компактности »: в пространстве объектов все близкие объекты должны относиться к одному кластеру, а все различные объекты соответственно должны находиться в различных кластерах.
Формальная постановка задачи кластеризации
Пусть - множество объектов, - множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами . Имеется конечная обучающая выборка объектов . Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами , так, чтобы каждый кластер состоял из объектов, близких по метрике , а объекты разных кластеров существенно отличались. При этом каждому объекту приписывается номер кластера .
Алгоритм кластеризации - это функция , которая любому объекту ставит в соответствие номер кластера . Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем, что метки исходных объектов изначально не заданы, и даже может быть неизвестно само множество .
Решение задачи кластеризации принципиально неоднозначно, и тому есть несколько причин (как считает ряд авторов):
- не существует однозначно наилучшего критерия качества кластеризации. Известен целый ряд эвристических критериев, а также ряд алгоритмов, не имеющих чётко выраженного критерия, но осуществляющих достаточно разумную кластеризацию «по построению». Все они могут давать разные результаты. Следовательно, для определения качества кластеризации требуется эксперт предметной области, который бы мог оценить осмысленность выделения кластеров.
- число кластеров, как правило, неизвестно заранее и устанавливается в соответствии с некоторым субъективным критерием. Это справедливо только для методов дискриминации, так как в методах кластеризации выделение кластеров идёт за счёт формализованного подхода на основе мер близости.
- результат кластеризации существенно зависит от метрики, выбор которой, как правило, также субъективен и определяется экспертом. Но стоит отметить, что есть ряд рекомендаций к выбору мер близости для различных задач.
Применение
В биологии
В биологии кластеризация имеет множество приложений в самых разных областях. Например, в биоинформатике с помощью нее анализируются сложные сети взаимодействующих генов, состоящие порой из сотен или даже тысяч элементов. Кластерный анализ позволяет выделить подсети, узкие места, концентраторы и другие скрытые свойства изучаемой системы, что позволяет в конечном счете узнать вклад каждого гена в формирование изучаемого феномена.
В области экологии широко применяется для выделения пространственно однородных групп организмов, сообществ и т. п. Реже методы кластерного анализа применяются для исследования сообществ во времени. Гетерогенность структуры сообществ приводит к возникновению нетривиальных методов кластерного анализа (например, метод Чекановского).
В общем стоит отметить, что исторически сложилось так, что в качестве мер близости в биологии чаще используются меры сходства , а не меры различия (расстояния).
В социологии
При анализе результатов социологических исследований рекомендуется осуществлять анализ методами иерархического агломеративного семейства, а именно методом Уорда, при котором внутри кластеров оптимизируется минимальная дисперсия, в итоге создаются кластеры приблизительно равных размеров. Метод Уорда наиболее удачен для анализа социологических данных. В качестве меры различия лучше квадратичное евклидово расстояние, которое способствует увеличению контрастности кластеров. Главным итогом иерархического кластерного анализа является дендрограмма или «сосульчатая диаграмма». При её интерпретации исследователи сталкиваются с проблемой того же рода, что и толкование результатов факторного анализа - отсутствием однозначных критериев выделения кластеров. В качестве главных рекомендуется использовать два способа - визуальный анализ дендрограммы и сравнение результатов кластеризации, выполненной различными методами.
Визуальный анализ дендрограммы предполагает «обрезание» дерева на оптимальном уровне сходства элементов выборки. «Виноградную ветвь» (терминология Олдендерфера М. С. и Блэшфилда Р. К. ) целесообразно «обрезать» на отметке 5 шкалы Rescaled Distance Cluster Combine, таким образом будет достигнут 80 % уровень сходства. Если выделение кластеров по этой метке затруднено (на ней происходит слияние нескольких мелких кластеров в один крупный), то можно выбрать другую метку. Такая методика предлагается Олдендерфером и Блэшфилдом.
Теперь возникает вопрос устойчивости принятого кластерного решения. По сути, проверка устойчивости кластеризации сводится к проверке её достоверности. Здесь существует эмпирическое правило - устойчивая типология сохраняется при изменении методов кластеризации. Результаты иерархического кластерного анализа можно проверять итеративным кластерным анализом по методу k-средних. Если сравниваемые классификации групп респондентов имеют долю совпадений более 70 % (более 2/3 совпадений), то кластерное решение принимается.
Проверить адекватность решения, не прибегая к помощи другого вида анализа, нельзя. По крайней мере, в теоретическом плане эта проблема не решена. В классической работе Олдендерфера и Блэшфилда «Кластерный анализ» подробно рассматриваются и в итоге отвергаются дополнительные пять методов проверки устойчивости:
В информатике
- Кластеризация результатов поиска - используется для «интеллектуальной» группировки результатов при поиске файлов , веб-сайтов , других объектов , предоставляя пользователю возможность быстрой навигации, выбора заведомо более релевантного подмножества и исключения заведомо менее релевантного - что может повысить юзабилити интерфейса по сравнению с выводом в виде простого сортированного по релевантности списка .
- Clusty - кластеризующая поисковая машина компании Vivísimo
- Nigma - российская поисковая система с автоматической кластеризацией результатов
- Quintura - визуальная кластеризация в виде облака ключевых слов
- Сегментация изображений (англ. image segmentation ) - Кластеризация может быть использована для разбиения цифрового изображения на отдельные области с целью обнаружения границ (англ. edge detection ) или распознавания объектов .
- Интеллектуальный анализ данных (англ. data mining) - Кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель для всех данных. Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой из них отдельную стратегию.
См. также
Примечания
Ссылки
На русском языке- www.MachineLearning.ru - профессиональный вики-ресурс, посвященный машинному обучению и интеллектуальному анализу данных
- COMPACT - Comparative Package for Clustering Assessment . A free Matlab package, 2006.
- P. Berkhin, Survey of Clustering Data Mining Techniques , Accrue Software, 2002.
- Jain, Murty and Flynn: Data Clustering: A Review , ACM Comp. Surv., 1999.
- for another presentation of hierarchical, k-means and fuzzy c-means see this introduction to clustering . Also has an explanation on mixture of Gaussians.
- David Dowe, Mixture Modelling page - other clustering and mixture model links.
- a tutorial on clustering
- The on-line textbook: Information Theory, Inference, and Learning Algorithms , by David J.C. MacKay includes chapters on k-means clustering, soft k-means clustering, and derivations including the E-M algorithm and the variational view of the E-M algorithm.
- «The Self-Organized Gene» , tutorial explaining clustering through competitive learning and self-organizing maps.
- kernlab - R package for kernel based machine learning (includes spectral clustering implementation)
- Tutorial - Tutorial with introduction of Clustering Algorithms (k-means, fuzzy-c-means, hierarchical, mixture of gaussians) + some interactive demos (java applets)
- Data Mining Software - Data mining software frequently utilizes clustering techniques.
- Java Competitve Learning Application A suite of Unsupervised Neural Networks for clustering. Written in Java. Complete with all source code.
- Machine Learning Software - Also contains much clustering software.
10.1.1 Основные понятия.
Пусть
исследуется совокупность
объектов,
каждый из которых характеризуется
 измеренными признаками. Требуется
разбить эту совокупность на однородные
в некотором смысле группы. При
этом практически отсутствует априорная
информация о характере распределения
измеренными признаками. Требуется
разбить эту совокупность на однородные
в некотором смысле группы. При
этом практически отсутствует априорная
информация о характере распределения
 -мерного
вектора
-мерного
вектора внутри классов.
Полученные
в результате разбиения группы обычно
называются кластерами
(таксонами, образами)
,
методы их нахождения - кластер-анализом
(численной таксономией или распознаванием
образов с самообучением).
внутри классов.
Полученные
в результате разбиения группы обычно
называются кластерами
(таксонами, образами)
,
методы их нахождения - кластер-анализом
(численной таксономией или распознаванием
образов с самообучением).
Решение задачи заключается в определении естественного расслоения результатов наблюдений на четко выраженные кластеры, лежащие друг от друга на некотором расстоянии. (Может оказаться, что множество наблюдений не обнаруживает естественного расслоения на кластеры, т.е. образует один кластер).
Обычной формой представления исходных данных в задачах кластерного анализа служит матрица
 ,
,
каждая
строка которой представляет результаты
измерений
 рассматриваемых признаков у одного из
объектов.
рассматриваемых признаков у одного из
объектов.
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные выборки представить как точки в признаковом пространстве, то задача кластеризации сводится к определению "сгущений точек".
Переводится понятие кластер (cluster) как "скопление", "гроздь". Синонимами термина " кластеризация " являются "автоматическая классификация ", "обучение без учителя" и "таксономия".
Цель кластеризации - поиск существующих структур. Кластеризация является описательной процедурой, она не делает никаких статистических выводов, но дает возможность провести разведочный анализ и изучить "структуру данных". Классы заранее не определены, осуществляется поиск наиболее похожих, однородных групп. Кластер можно охарактеризовать как группу объектов, имеющих общие свойства.
Характеристиками кластера можно назвать два признака:
внутренняя однородность;
внешняя изолированность.
Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и пересекающимися (overlapping). Схематическое изображение непересекающихся и пересекающихся кластеров дано на рис. 10.1.
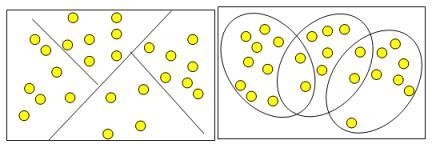
Рис. 10.1 Непересекающиеся и пересекающиеся кластеры
Термин «кластерный анализ», впервые введенный Трионом (Tryon) в 1939 году, объединяет более 100 различных алгоритмов.
В отличие от задач классификации, кластерный анализ не требует априорных предположений о наборе данных, не накладывает ограничения на представление исследуемых объектов, позволяет анализировать показатели различных типов данных (интервальные данные, частоты, бинарные данные). При этом необходимо помнить, что переменные должны измеряться в сравнимых шкалах.
10.1.2 Характеристики кластера
Кластер имеет следующие математические характеристики: центр, радиус, среднеквадратическое отклонение, размер кластера.
Каждый объект совокупности в кластерном анализе рассматривается как точка в заданном признаковом пространстве. Значение каждого из признаков у данной единицы служит ее координатой в этом пространстве.
Центр кластера - это среднее геометрическое место точек в пространстве переменных.
Радиус кластера - максимальное расстояние расположения точек от центра кластера.
Если невозможно при помощи математических процедур однозначно отнести объект к одному из двух кластеров, то такие объекты называют спорными, и обнаруживается перекрытие кластеров. Спорный объект - это объект, который по мере сходства может быть отнесен к нескольким кластерам.
Размер кластера может быть определен либо по радиусу кластера, либо по среднеквадратичному отклонению объектов для этого кластера. Объект относится к кластеру, если расстояние от объекта до центра кластера меньше радиуса кластера. Если это условие выполняется для двух и более кластеров, объект является спорным. Неоднозначность данной задачи может быть устранена экспертом или аналитиком.
С понятием кластеризации мы познакомились в первом разделе курса. В этой лекции мы опишем понятие " кластер " с математической точки зрения, а также рассмотрим методы решения задач кластеризации - методы кластерного анализа.
Термин кластерный анализ , впервые введенный Трионом (Tryon) в 1939 году, включает в себя более 100 различных алгоритмов.
В отличие от задач классификации, кластерный анализ не требует априорных предположений о наборе данных, не накладывает ограничения на представление исследуемых объектов, позволяет анализировать показатели различных типов данных (интервальным данным, частотам, бинарным данным). При этом необходимо помнить, что переменные должны измеряться в сравнимых шкалах.
Кластерный анализ позволяет сокращать размерность данных, делать ее наглядной.
Кластерный анализ может применяться к совокупностям временных рядов, здесь могут выделяться периоды схожести некоторых показателей и определяться группы временных рядов со схожей динамикой.
Кластерный анализ параллельно развивался в нескольких направлениях, таких как биология, психология, др., поэтому у большинства методов существует по два и более названий. Это существенно затрудняет работу при использовании кластерного анализа.
Задачи кластерного анализа можно объединить в следующие группы:
- Разработка типологии или классификации.
- Исследование полезных концептуальных схем группирования объектов.
- Представление гипотез на основе исследования данных.
- Проверка гипотез или исследований для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Как правило, при практическом использовании кластерного анализа одновременно решается несколько из указанных задач.
Рассмотрим пример процедуры кластерного анализа.
Допустим, мы имеем набор данных А, состоящий из 14-ти примеров, у которых имеется по два признака X и Y. Данные по ним приведены в таблице 13.1 .
| № примера | признак X | признак Y |
|---|---|---|
| 1 | 27 | 19 |
| 2 | 11 | 46 |
| 3 | 25 | 15 |
| 4 | 36 | 27 |
| 5 | 35 | 25 |
| 6 | 10 | 43 |
| 7 | 11 | 44 |
| 8 | 36 | 24 |
| 9 | 26 | 14 |
| 10 | 26 | 14 |
| 11 | 9 | 45 |
| 12 | 33 | 23 |
| 13 | 27 | 16 |
| 14 | 10 | 47 |
Данные в табличной форме не носят информативный характер. Представим переменные X и Y в виде диаграммы рассеивания, изображенной на рис. 13.1 .
Рис.
13.1.
На рисунке мы видим несколько групп "похожих" примеров. Примеры (объекты), которые по значениям X и Y "похожи" друг на друга, принадлежат к одной группе (кластеру); объекты из разных кластеров не похожи друг на друга.
Критерием для определения схожести и различия кластеров является расстояние между точками на диаграмме рассеивания. Это сходство можно "измерить", оно равно расстоянию между точками на графике. Способов определения меры расстояния между кластерами, называемой еще мерой близости, существует несколько. Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i и j на плоскости, когда известны их координаты X и Y:
Примечание: чтобы узнать расстояние между двумя точками, надо взять разницу их координат по каждой оси, возвести ее в квадрат, сложить полученные значения для всех осей и извлечь квадратный корень из суммы.
Когда осей больше, чем две, расстояние рассчитывается таким образом: сумма квадратов разницы координат состоит из стольких слагаемых, сколько осей (измерений) присутствует в нашем пространстве. Например, если нам нужно найти расстояние между двумя точками в пространстве трех измерений (такая ситуация представлена на рис. 13.2), формула (13.1) приобретает вид:

Рис. 13.2.
Кластер имеет следующие математические характеристики : центр , радиус , среднеквадратическое отклонение , размер кластера .
Центр кластера - это среднее геометрическое место точек в пространстве переменных.
Радиус кластера - максимальное расстояние точек от центра кластера .
Как было отмечено в одной из предыдущих лекций, кластеры могут быть перекрывающимися. Такая ситуация возникает, когда обнаруживается перекрытие кластеров. В этом случае невозможно при помощи математических процедур однозначно отнести объект к одному из двух кластеров. Такие объекты называют спорными .
Спорный объект - это объект , который по мере сходства может быть отнесен к нескольким кластерам.
Размер кластера может быть определен либо по радиусу кластера , либо по среднеквадратичному отклонению объектов для этого кластера. Объект относится к кластеру, если расстояние от объекта до центра кластера меньше радиуса кластера . Если это условие выполняется для двух и более кластеров, объект является спорным .
Неоднозначность данной задачи может быть устранена экспертом или аналитиком.
Работа кластерного анализа опирается на два предположения. Первое предположение - рассматриваемые признаки объекта в принципе допускают желательное разбиение пула (совокупности) объектов на кластеры. В начале лекции мы уже упоминали о сравнимости шкал, это и есть второе предположение - правильность выбора масштаба или единиц измерения признаков.
Выбор масштаба в кластерном анализе имеет большое значение . Рассмотрим пример. Представим себе, что данные признака х в наборе данных А на два порядка больше данных признака у: значения переменной х находятся в диапазоне от 100 до 700, а значения переменной у - в диапазоне от 0 до 1.
Тогда, при расчете величины расстояния между точками, отражающими положение объектов в пространстве их свойств,
В ходе экспериментов возможно сравнение результатов, полученных с учетом экспертных оценок и без них, и выбор лучшего из них.
Каждая из групп включает множество подходов и алгоритмов.
Используя различные методы кластерного анализа, аналитик может получить различные решения для одних и тех же данных. Это считается нормальным явлением. Рассмотрим иерархические и неиерархические методы подробно.
Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров в большие или разделении больших кластеров на меньшие.
Иерархические агломеративные методы (Agglomerative Nesting, AGNES)Эта группа методов характеризуется последовательным объединением исходных элементов и соответствующим уменьшением числа кластеров.
В начале работы алгоритма все объекты являются отдельными кластерами. На первом шаге наиболее похожие объекты объединяются в кластер. На последующих шагах объединение продолжается до тех пор, пока все объекты не будут составлять один кластер. Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA)Эти методы являются логической противоположностью агломеративным методам. В начале работы алгоритма все объекты принадлежат одному кластеру, который на последующих шагах делится на меньшие кластеры, в результате образуется последовательность расщепляющих групп.
Неиерархические методы выявляют более высокую устойчивость по отношению к шумам и выбросам, некорректному выбору метрики, включению незначимых переменных в набор, участвующий в кластеризации. Ценой, которую приходится платить за эти достоинства метода, является слово "априори". Аналитик должен заранее определить количество кластеров, количество итераций или правило остановки, а также некоторые другие параметры кластеризации. Это особенно сложно начинающим специалистам.
Если нет предположений относительно числа кластеров, рекомендуют использовать иерархические алгоритмы. Однако если объем выборки не позволяет это сделать, возможный путь - проведение ряда экспериментов с различным количеством кластеров, например, начать разбиение совокупности данных с двух групп и, постепенно увеличивая их количество, сравнивать результаты. За счет такого "варьирования" результатов достигается достаточно большая гибкость кластеризации.
Иерархические методы, в отличие от неиерархических, отказываются от определения числа кластеров, а строят полное дерево вложенных кластеров.
Сложности иерархических методов кластеризации: ограничение объема набора данных; выбор меры близости; негибкость полученных классификаций.
Преимущество этой группы методов в сравнении с неиерархическими методами - их наглядность и возможность получить детальное представление о структуре данных.
При использовании иерархических методов существует возможность достаточно легко идентифицировать выбросы в наборе данных и, в результате, повысить качество данных. Эта процедура лежит в основе двухшагового алгоритма кластеризации. Такой набор данных в дальнейшем может быть использован для проведения неиерархической кластеризации.
Существует еще одни аспект, о котором уже упоминалось в этой лекции. Это вопрос кластеризации всей совокупности данных или же ее выборки. Названный аспект существенен для обеих рассматриваемых групп методов, однако он более критичен для иерархических методов. Иерархические методы не могут работать с большими наборами данных, а использование некоторой выборки, т.е. части данных, могло бы позволить применять эти методы.
Результаты кластеризации могут не иметь достаточного статистического обоснования. С другой стороны, при решении задач кластеризации допустима нестатистическая интерпретация полученных результатов, а также достаточно большое разнообразие вариантов понятия кластера. Такая нестатистическая интерпретация дает возможность аналитику получить удовлетворяющие его результаты кластеризации, что при использовании других методов часто бывает затруднительным.
1) Метод полных связей.
Суть данного метода в том, что два объекта, принадлежащих одной и той же группе (кластеру), имеют коэффициент сходства, который меньше некоторого порогового значения S. В терминах евклидова расстояния d это означает, что расстояние между двумя точками (объектами) кластера не должно превышать некоторого порогового значения h. Таким образом, h определяет максимально допустимый диаметр подмножества, образующего кластер.
2) Метод максимального локального расстояния.
Каждый объект рассматривается как одноточечный кластер. Объекты группируются по следующему правилу: два кластера объединяются, если максимальное расстояние между точками одного кластера и точками другого минимально. Процедура состоит из n - 1 шагов и результатом являются разбиения, которые совпадают со всевозможными разбиениями в предыдущем методе для любых пороговых значений.
3) Метод Ворда.
В этом методе в качестве целевой функции применяют внутригрупповую сумму квадратов отклонений, которая есть ни что иное, как сумма квадратов расстояний между каждой точкой (объектом) и средней по кластеру, содержащему этот объект. На каждом шаге объединяются такие два кластера, которые приводят к минимальному увеличению целевой функции, т.е. внутригрупповой суммы квадратов. Этот метод направлен на объединение близко расположенных кластеров.
4) Центроидный метод.
Расстояние между двумя кластерами определяется как евклидово расстояние между центрами (средними) этих кластеров:
d2 ij = (`X -`Y)Т(`X -`Y) Кластеризация идет поэтапно на каждом из n-1 шагов объединяют два кластера G и p, имеющие минимальное значение d2ij Если n1 много больше n2, то центры объединения двух кластеров близки друг к другу и характеристики второго кластера при объединении кластеров практически игнорируются. Иногда этот метод иногда называют еще методом взвешенных групп.













